
看你长得像个活人


事件的起因其实我今早在微博说了一下。有一些人民群众写了篇(英文的)文章,扔到AI检测系统里面去,结果被判31分。人民群众就觉得这个分数有点高,于是就找了我这个英文怪水的人来改一下。
我捋了捋逻辑什么的,大概给改了十分钟吧。然后发回去。
人民群众:你干了什么?! 现在67分了!
我:那我就是直接改的,下回我给你用修改好吧,这次我真的记不清了。
人民群众:没有下回了!
说实在话,这个问题现在挺普遍的。学校交个作业,杂志投个稿什么的,老师主编往往第一步就是把文章扔到AI检测系统里头去。所以也难怪同学们索性主动出击,自己先测一下。但是这个问题是这样的,从商业逻辑看,只要你敢扔,他就一定敢给你打高分。
为什么?分数低的话,怎么卖给你humanize服务啊。你看我早上连读带改,也就十分钟。我自己觉得大概也就捋了四五个地方,那在一篇1000 words的文章里是在是九牛一毛的一毛。但是一毛一变,系统立刻翻脸。你觉得我能touch 了文章多少啊?可见这个判断对与我给予的微小变化的权重及其敏感,或者对于修改本身及其敏感。我英语也就是个二五眼,我觉得我没那么精妙。
这件事情本身呢,在我看就是一件很搞笑的事情。
什么是‘像人写的’?了解LLM的同学们会非常轻易的看出来,这就是一个pattern recognition (模式识别), 大部分人类的英语嘛,和LLM写的比起来看,可能没有那么圆滑流畅,用词可能也比较窄。 不会有很多破折号,什么什么的。这个大约就是判定的基础。人民群众觉得31分比较高,其实真的算不了什么。我给你们看看丘吉尔的一段话,那系统觉得就是个AI 写的。
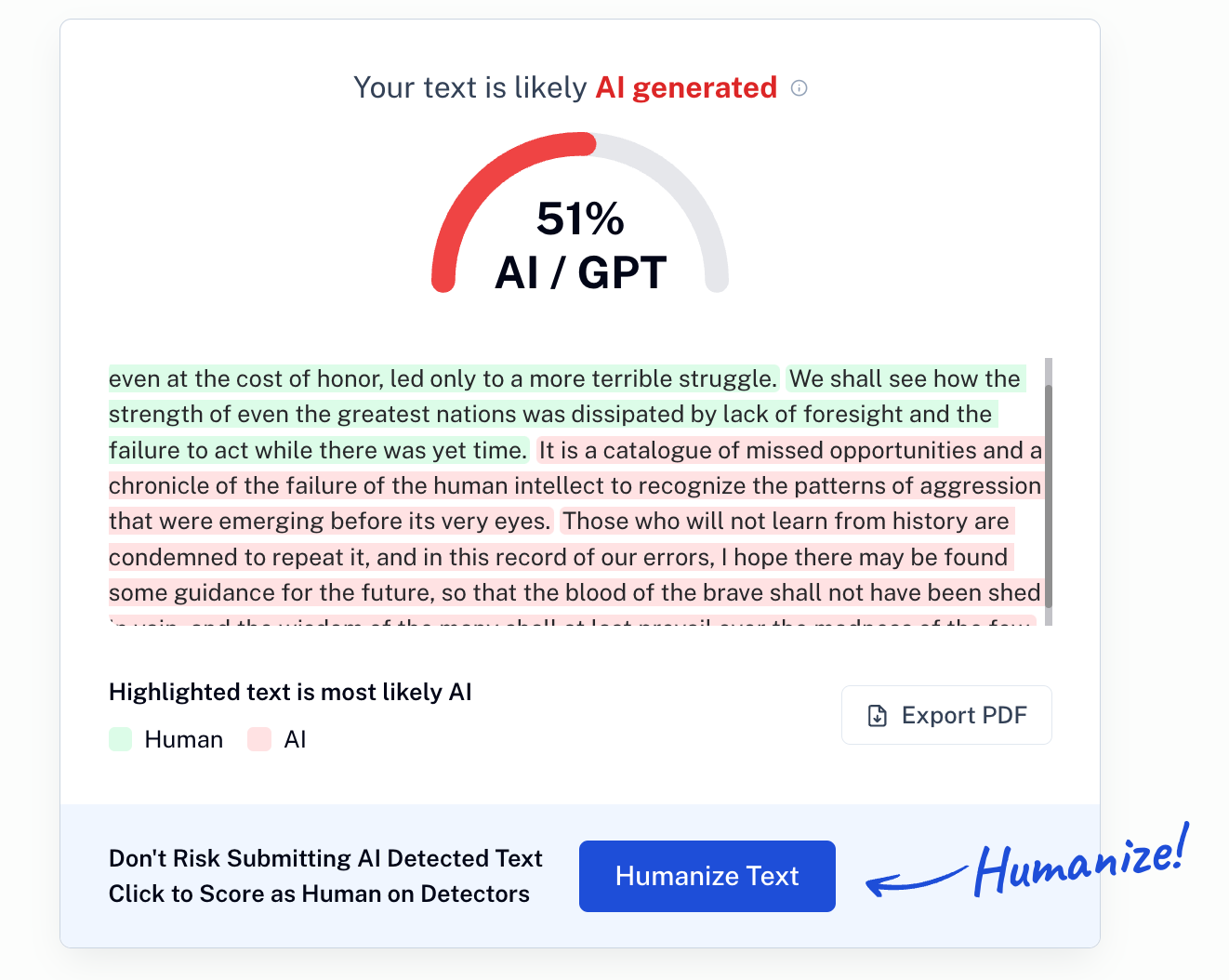
所以这件事本身,在我看来就是个玄学。
为什么?大模型本身呢,有pre-train, 有 training, 有post-train, 基本上呢整个过程就是一个让概率模型‘吐字像人’的‘对齐’过程。尤其是RLHF的过程中,我们会让人类来给予模型的输出提出反馈,以进一步让模型和人类语言‘对齐’。你对来对去的,对的这么齐了,你猜猜对齐的是谁的英语水平?
以我今早的遭遇来看,假设人民群众选择使用‘humanize text', 那这个东西是什么?不过是这个工具所使用的模型以某种‘不像AI’的方式来输出同一个意思的文字。那么问题来了,三个问题:
- 我们可以预见改完以后分数巨低,说不定是0. 但是这有什么意义吗?左手修改,右手裁判,听起来真带劲
- 所以你告诉我用LLM来生成‘更像人’的文字是可行的?那你用的哪家的模型啊?是不是可以说明,用他家的LLM来生成‘更像人’的文字本身是可行的?你绕一绕就能绕明白,要不就是测不出来,要不就是改不出来。矛和盾不可能都是最棒的。
- 万一写的不是特别对或者不是特别好,你改完了还能行吗?万一你忍不住改了10分钟,又67分了呢?这下出不来了。
所以要我说,这个游戏就是一个坑人的事情。作为人民群众,你们不应该陪玩。只要敢玩,就一定输。
我倒是想跟诸位老师教授们说一句:这个方式本身太粗暴了。作业就那么多,你们耐心一点看一看嘛。其实是不是人写的,在现阶段很好看。主意是人的就行了。